Summary of the AlexNet paper: one of the most influential papers in computer vision
Introduction:
AlexNet is the name of the convolutional neural network (CNN) designed by Alex Krizhevsky in collaboration with Ilya Sutskever and Geoffrey Hinton at the university of Toronto, the CNN competed in the imagenet challenge on September 30, 2012.
The network influential nature came from it’s use of GPU to accelerate deep learning, even though it was not the first to do so nonetheless the AlexNet paper was cited over 80,00 times influencing many other papers and research into using GPUs to accelerate deep learning.
Procedures:
The purpose of alexnet was clear from the paper, they trained one of the largest CNN at that time with a highly optimized multi-GPU implementation while also avoiding overf-fitting, with that said let’s into the details.
The Data:
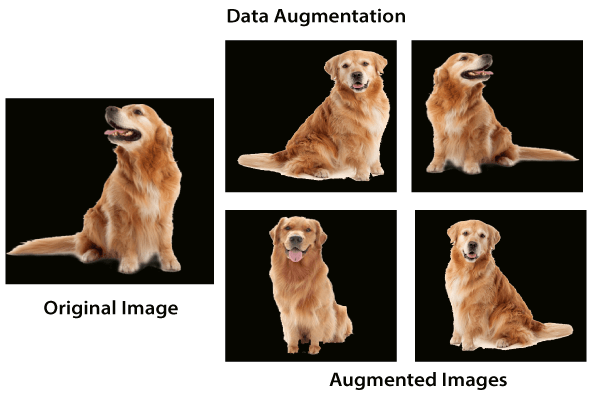
For the dataset the team used imagenet, it has variable length high-resolution images for which they needed to down-scale down to 256x256, first given the rectangular nature of the image they scaled down so that the shorter side is 256 and then cropped the center of the image with the appropriate dimension and for the RGB values they subtracted the mean of the values of the training set.
They also used Data Augmentation which is a very effective method in countering over-fitting, and as the name suggests it generates bunch of images from one image by transforming it.
For alexnet the researchers used two methods of augmentation, both of which used little computation as they where handled by the CPU:
-
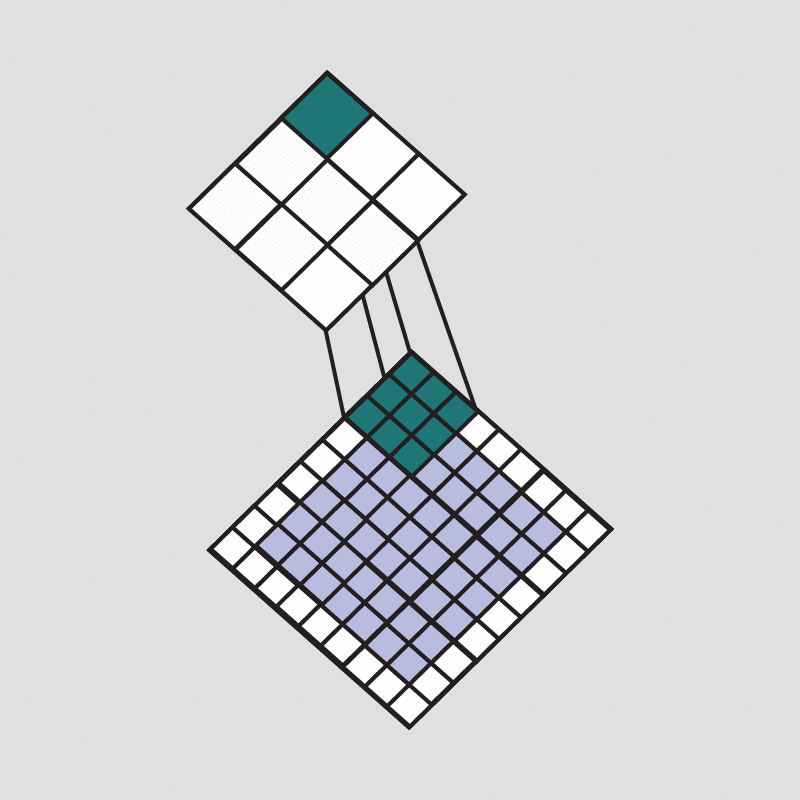
The first method consists of generating image translations and reflections (sliding the image in the x and y axis or filliping it sideways, see the picture above), the resulting side is always a 224x224 image from the 256x256 original one.
-
the second form of data augmentation consists of altering the intensities of the RGB channels, specifically they used PCA (principal component analysis, a method of analyzing highly dimensional data), so to each training image they add multiples of the found principle components with magnitudes proportional to the corresponding eigenvalues times a random variable drawn from a Gaussian (normal distribution) with mean zero and standard deviation 0.1, This scheme is used so that the image identity is invariant to the changes in intensity and color of the illumination.
Architecture:
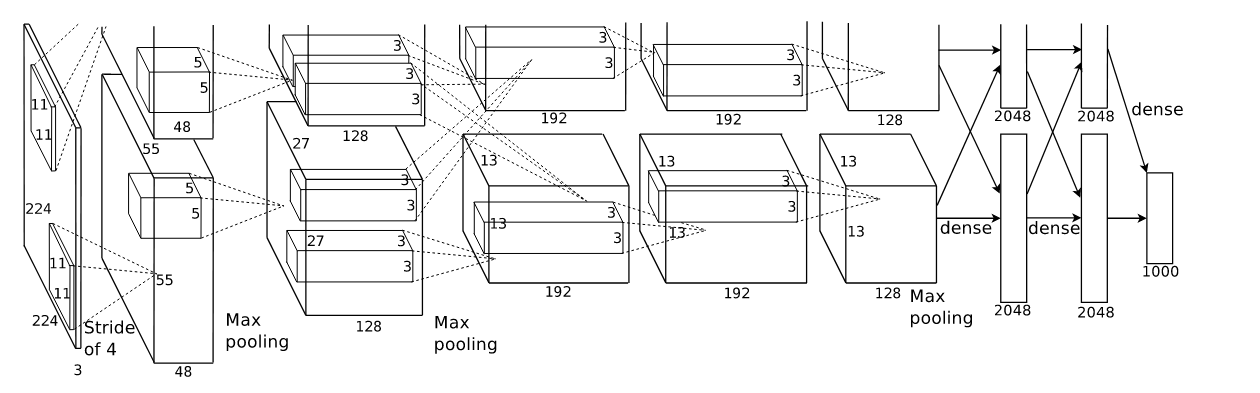
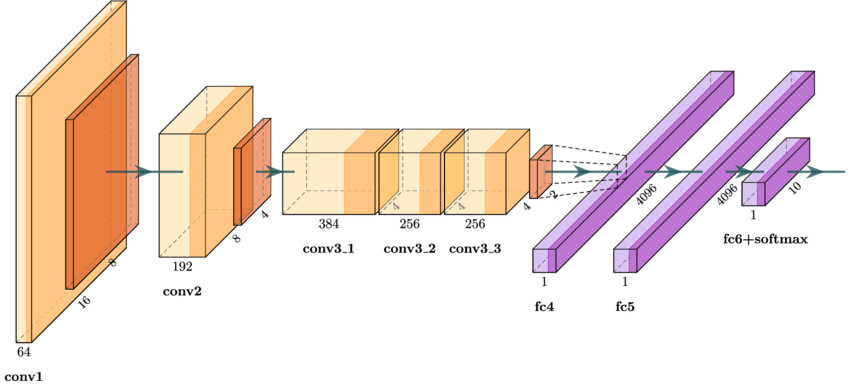
The architecture of alexnet is as follows, it consists of eight learned layers, five convolutional ones, and three fully connected. the researchers opted for the ReLU activation when at the time was not standard instead of Tanh, with the following figure to show the superiority of the non-linearity.
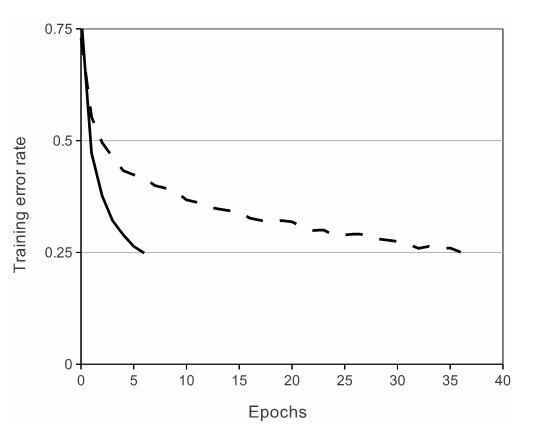
The dashed line being tanh and the continuous one is ReLU, the function is also several times faster in CNNs.
The researchers also employed Multi-GPU for the fact that they share memory, therefore they spread the network over them with each GPU taking half of the of the layers and communicating back and forth when needed.
They used LRN (local response normalization) which is a type of non trainable normalization layer done after activation that aids the network in generalization it’s similar to an effect observed in real neurons lateral inhibition, which creates a sort of competition between neurons, in the paper it’s used across channels with the following formula,
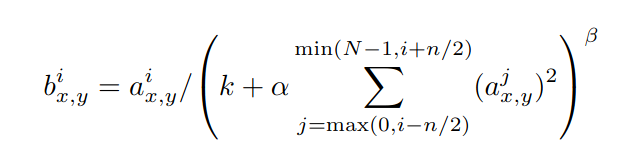
In the paper they also used dropout which was a recently introduced technique at the time but it had a significant impact on reducing over-fitting, the author of the papers saw the method as training a slightly different architecture each time which was a really novel way to see this technique for me.
Initialization and Training:
The weights where initialized from a zero mean Gaussian distribution with standard deviation of 0.01.
For biases for the second, fourth and fifth conv layers as well as the fully connected layers they were initialized with with constant 1, this accelerates the early stages of learning as by providing ReLU with a positive input and for the others the constant 0.
The learning rate was initialized at 0.01 and was adjusted manually throughout training and ways divided by 10 when it was noticed that the validation error stopped improving.
Results:

these are some of the results shown in the paper:
the name under images show the actual label and the bars show the percentage of the top-5 labels finally the pink in the bars show the actual class.
For the imagenet competition submission the authors received a top-1 score (which is the error rate of predicted class against the actual class) of 37.5% and top-5 score (which is the error rate of if the actual class is in the top five predicted classes) of 17% which was an improvement over the current models at the time with top-1 and top-5 scores of 45.7% and 25.7% respectively.
Conclusion and personal notes:

The results obtained in the study indicate that large, and deep convolutional neural networks have immense potential into the field of computer vision.
it was also notable that the performance degrades if a single convolutional layer is removed, “For example, removing any of the middle layers results in a loss of about 2% for the top-1 performance of the network”.
This shows that depth is very important in CNNs which after this study went through a lot of changes from vggnet with it’s 19 layers of convolutions to resnets with their 152 layers and their skip connection which elevate over-fitting.
The world of CNNs has seen so much progress in recent years but it wouldn’t be achieved without the advancements in GPU technology, which historically is similar as the advancement of science as the result of advancements of tools, as tools become an enabler of experimentation that lead to theories and papers.